glibc 汇编中的cfi_xxx指令与一些宏定义的说明
[TOC]
- 最近在看glibc中的一些源码, 涉及到一些系统底层操作时, 需要看汇编代码, 发现了一些cfi_xxx开头的调用,这里梳理下
- 这里以32位下i386架构说明, sysdep文件在:
glibc/sysdeps/i386/sysdep.h
ENTRY/END 宏
- sysdep中的ENTRY/END 用来定义汇编函数的开始/结束
- 比较反直觉的是, 这里定义的代码, 全部是汇编指令, 不会再编译后的代码中出现,
- 并不是push %ebp; move %ebp %esp; 这种标准c调用开头语结尾
ENTRY
1 | #define ENTRY(name) \ |
- 逐句说明:
- .globl C_SYMBOL_NAME(name);.type C_SYMBOL_NAME(name),@function;
- 这两句简单, 大家都看得懂, 声明一个全局符号, 定义一个函数名
- .align ALIGNARG(4);

- 地址对齐, 方便在一个指令周期内拿到数据
C_LABEL(name)
1
2/* Define a macro we can use to construct the asm name for a C symbol. */
# define C_LABEL(name) name##:- 函数名+”:”, 用于jmp
- cfi_startproc
- cfi_xx系列调用, 后面再说
CALL_MCOUNT
1
2
3
4
5
6
7#define CALL_MCOUNT \
pushl %ebp; cfi_adjust_cfa_offset (4); movl %esp, %ebp; \
cfi_def_cfa_register (ebp); call JUMPTARGET(mcount); \
popl %ebp; cfi_def_cfa (esp, 4);
#else
#define CALL_MCOUNT /* Do nothing. */
#endif- 用于性能分析时, 计数这个函数的调用次数用的, 不开相关宏的话, 不会体现在代码里.

- .globl C_SYMBOL_NAME(name);.type C_SYMBOL_NAME(name),@function;
END
1 | #undef END |
ASM_SIZE_DIRECTIVE
1
#define ASM_SIZE_DIRECTIVE(name) .size name,.-name
- 计算这一段的长度, 不会再编译后生成, 只是告诉编译器,这一段的长度
cfi_xxx系列调用
- 现在只剩cfi_xxx 的调用了, 文档看得不明所以, 我太菜了T_T
- 下面的是我结合
DWARF4官方文档的理解
dwarf
- DWARF: Debugging Information Format 调试信息格式
- 一种用于定义兼容的调试信息的格式定义, 可以用于
f Ada, C, C++, COBOL, and Fortran; - 但这种信息需要额外的编译时支持, 需要在编译时, 明确的告知编译器, 哪里是函数开始, 结束, 每次esp发生变化时, 都要进行对齐
- 当然, 这些都是编译时指令, 在最终的二进制中, 不会再运行的代码中出现
eh_frame段
- gcc在调用stackTrace, 处理异常信息 , 需要额外的数据来进行堆栈的展开, 这些信息就是保存在eh_frame段中的
- 这些信息是在编译时, 通过cfi_xxx系列的编译器指令来实现保存的
- 这些指令只在编译时生效, 用于生成eh_frame中的数据
- 最终的.o中, 是没有这些编译指令的
cfi_xxx 指令

- cfi Call Frame Information 调用帧信息
- 分配在堆栈上的内存区域,称为“调用帧”, “调用帧由堆栈上的地址标识。
- CFA Canonical Frame Address 规范框架地址
- 通过cfi信息, 可以实现断点, debug栈展开, 异步事件的中断等功能
- 现在,根据gnubinutile/as说明, 就可以很清晰的理解cfi的具体作用了

- 开支定义一个函数的cfi信息, 结束函数的cfi信息, 计算偏移量, 定义CFA开始等等各种操作, 这里就不列举列, 了解它的作用后,文档里面描述就很清晰了
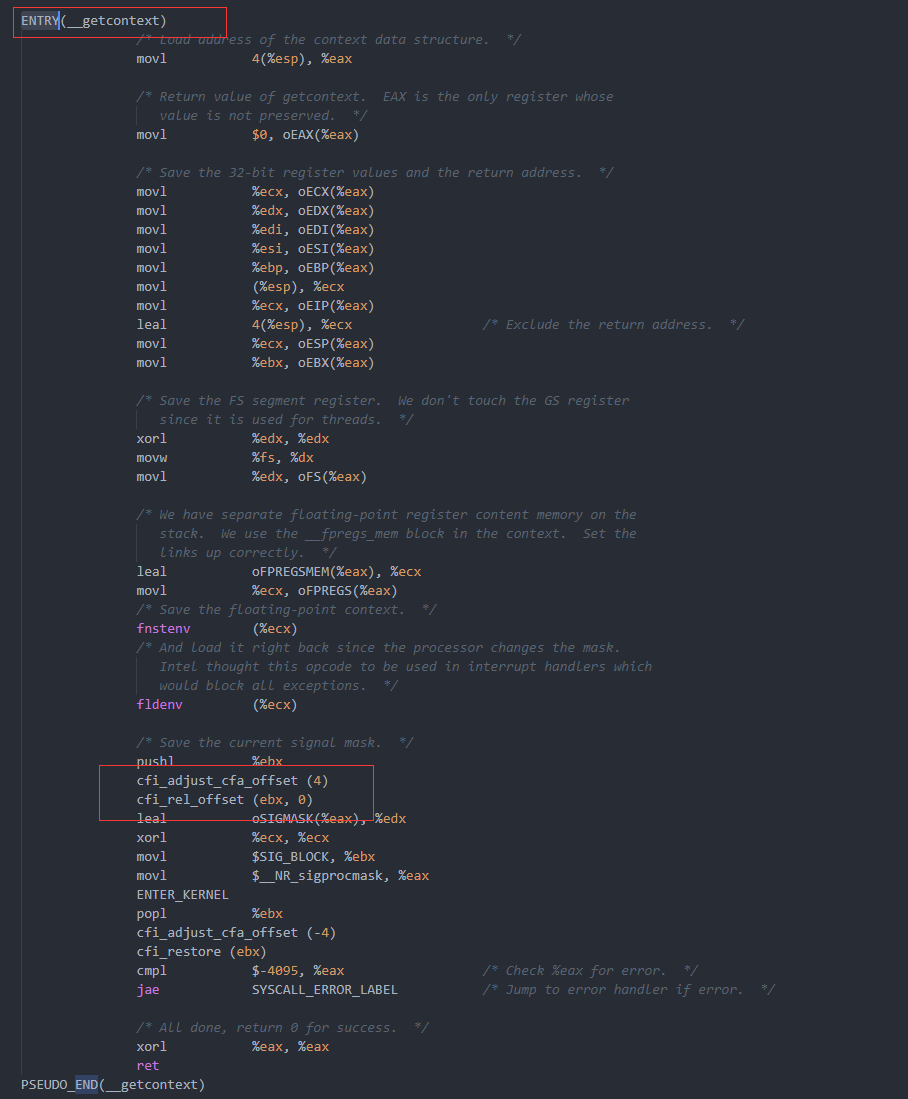
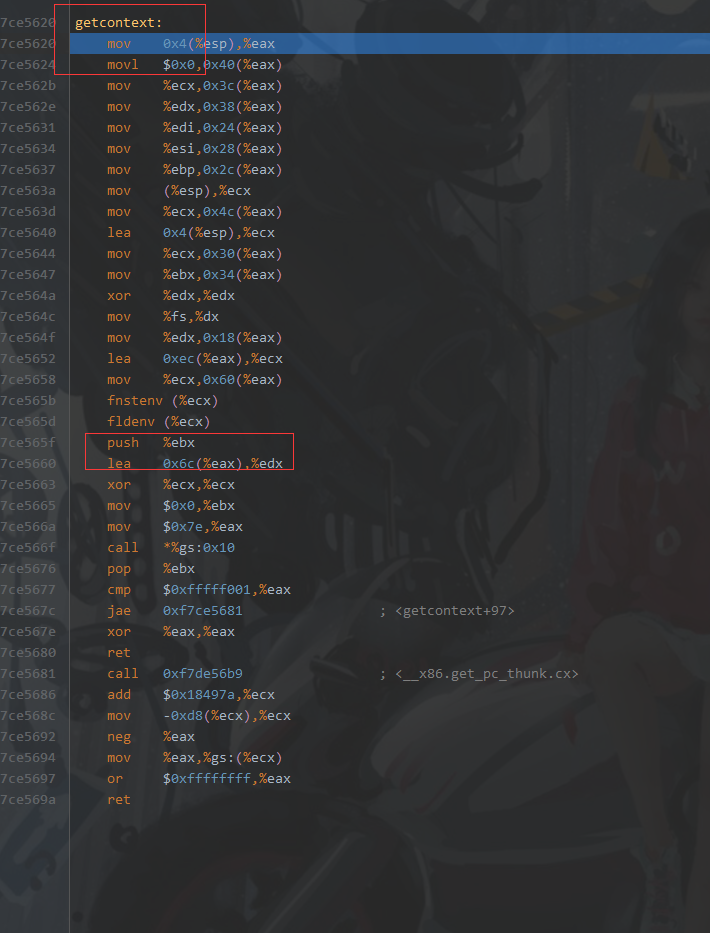
例子
- 最后, 放一个 getcontext 函数的 glibc汇编源码与编译后的反汇编代码的区别, 就可以证明这些